
League of Legends is the most popular MOBA game over the past four years for its high competitivity and excellent balance. Every player wants to win, but each one has almost identical chance of winning a match by default. However, there are inevitably several factors that will make a player more likely to win or more likely to lose, while one of the factors, the team composition, will be investigated in our project. The objective of this project is to predict the winner of a match when given the compositions of both teams. With the Smart Winner Predictor implemented, players are able to reference when picking their champions, as a result of boosting their winning rate.
Several learners have been tested while Naive Bayes gives the best performance and has been selected as the final learner. Due to the big champion pool of 126 champions and the high fidelity of champion selection, there can seldom be found two identical matches. Besides, every champion selection is also independent of each other, while independence is the key Assumption for Naive Bayes.
50,000 dataset instances that contain team composition and winner have been acquired using the official API of league of legends. Models have been trained based on the dataset, and the 10-folder cross-validation has been applied for validation, with Weka has been utilized as the software tool. The trained model is able to give the prediction of the winner when given compositions of both teams.
A validation accuracy of 55.3% has been generated using general Naive Bayes while other learners generate accuracies lower than 53%. The result is overall reasonable in sense, but beyond expectation. This shows the output of the predictor has 55.3% confidence, which also means the selected team has a win rate of 55.3%. Compared to the default win rate of 50%, a 5.3% boost is satisfactory. Champion’s internal relations and players’ different levels of skills on one certain champion become the most two reason of the 55.3% accuracy. Please see Result section for detailed explanation.
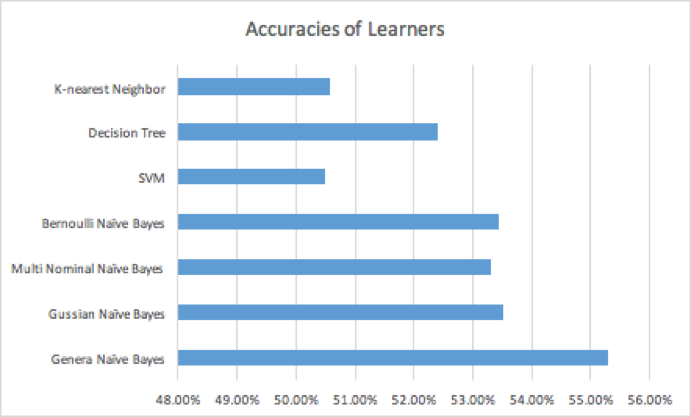
Figure 1: Accuracies of different learners
The accuracies of all learners that have been tried are presented. Naive Bayes performs well among these learners, while General Naive Bayes gives the best accuracy. Naive Bayes is suitable for this case, because each champion selection is considered independent to each other, which is the key assumption for Naive Bayes.
League of legends has become the most popular game over the past four years. To those who are not familiar with the game, League of Legends is an online MOBA (multiplayer online battle arena) game which two teams fight against each other, with the goal of destroying enemy team’s Nexus (an important building...). A team wins if they have successfully destroyed the enemy Nexus. Each team is made up of 5 players, and each teammate will choose a champion from the 128 Champion pool and play as the selected champion for the duration of the match. The objective of this project is to predict the winner of a match when given the compositions of both teams.
Since each champion is of being unique and there are so many possible combinations of champions, every match has been made exciting. Admittedly, different players are familiar different champions and own different levels of skills. Standing on the principle fairness, LOL utilizes its algorithm that assign teammates based on the same level of skills. Despite player skills that are pre-established, team composition has been commonly recognized as one of the most important factors that influences win rate. In other words, a good team composition could result in a much higher win rate against the other team, when both team players are at the same level of skills.
50,000 dataset instances that contains team composition and winner have been acquired using the official API of league of legends. Based on that, several different machine learning algorithms, specifically Naive Bayes, Support Vector Machine, Decision Tree and k-Nearest Neighbour. Models have been trained based on the dataset, and the 10-folder cross-validation has been applied for validation, with Weka has been utilized as the software tool. The trained model is able to give the prediction of the winner when given compositions of both teams.
The dataset has been acquired using Riot API with selected attributes. We specify 10 champions as the 10 attributes of a instance and a winner tag as result of a instance. We have acquired 1000 examples currently for testing purpose. Most of the instances are from division platinum or above since we expect users are relatively familiar with their selected champions, and we assume players under platnium won’t have a stable performance on selected champions that bring noise to our dataset. 50,000 instances have been acquired for testing or validation purposes.
Naive Bayes methods are a set of supervised learning algorithms based on applying Bayes’ theorem with the “naive” assumption of independence between every pair of features. Given a class variable and a dependent feature vector through , Bayes’ theorem states the following relationship:
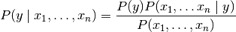
Specifically in our case, y represents the winner probability and x1 to xn serves as the given ten champions. The accuracy calculated by general Naive Bayes is 55.3%.
The Gaussian Naive Bayes implements the Gaussian Naive Bayes algorithm for classification that the likelihood of the features is assumed to be Gaussian. The accuracy calculated by Gaussian Naive Bayes is 53.51%.
The Multinomial Naive Bayes implements the naive Bayes algorithm for multinomially distributed data, and is one of the two classic naive Bayes variants used in text classification (where the data are typically represented as word vector counts, although tf-idf vectors are also known to work well in practice). The accuracy calculated by Gaussian Naive Bayes is 54.3%.
The Bernoulli Naive Bayes implements the naive Bayes training and classification algorithms for data that is distributed according to multivariate Bernoulli distributions. The accuracy calculated by Bernoulli Naive Bayes is 53.45%.
The model produced by support vector classification (as described above) depends only on a subset of the training data, because the cost function for building the model does not care about training points that lie beyond the margin. Analogously, the model produced by Support Vector Regression depends only on a subset of the training data, because the cost function for building the model ignores any training data close to the model prediction.
In our implementation, we created vector C = [C1, C2, …, C126] representing the 126 champions. When a champion, for example C10, has been selected by players from team 1, C10 becomes 1 in C; when it is selected by team 2, C10 becomes -1 instead. All champions unselected will be left at 0. The accuracy calculated by SVM is 50.5%.
Decision Tree is one of the simplest machine learning model that has been yet developed. Attributes of the ten champions will be set as nominal as well as the winner output. The tree will then be generated from datasets, and pruned afterwards. The accuracy calculated by Decision Tree is 52.40%.
K-Nearest neighbor is the instance based learning that identify instances locally in distance. However, since all attributes in our datasets are nominal that doesn’t own a distance, K-Nearest Neighbor does perform poorly. The accuracy calculated by K-Nearest Neighbor is 50.58%.
The result accuracies given by each learner have been presented in Figure 1, and the highest accuracy is given by General Naive Bayes as 55.3%. It is noticeable that all learners don’t perform well on the dataset. The objective and subjective reasons are listed below.
First of all, although all champions are picked independently, the internal relationships between champions do affect the accuracy. It is also noticed when analyzing only one champion versus the other champion (ignoring the rest four attributes of each team), the accuracy can reach up to 87% compared to 55.3%; but when more attributes (champions) are introduced, accuracy goes down not only due to the model complexity but also for some internal relations within champion selection. Let’s take an example for illustration, the accuracy of Malphite vs MordeKaiser is 74% in favor of MordeKaiser; however when an additional attribute, Orianna has been introduced; the accuracy of Malphite + Orianna vs Vladimir decrease to 65%. Malphite is very weak against MordeKaiser, but the internal relation between Malphite and Orianna boosts the win rate for Malphite since they two cooperates very well. It is also foreseened that when even more attributes are introduced, the accuracy will continue changing.
Secondly, the accuracy will eventually drop to close to 50% when players picking champions. Because of these internal relationships, players will select their champions that best boost win rate; when all players are trying to do that, the match reach balanced and win rate of each team will eventually be close to 50%. This will also give an accuracy close to 50%.
Last but not least, the subjective reason, that players own different levels of skills on certain champions, affects the accuracy. When assembling teams, League of Legends does not consider player’s skill at certain champion but their overall skills. However, even when using the same champion against the same enemy champion, different players will give out different performances, leading to either winning or losing output.
Considering the three factors above, it is really hard to achieve a good accuracy (over 60%) when analyzing only team compositions to predict results.
This project focuses on the predicting the winner when given team compositions. It turns out that the highest accuracy is only as high as 55.3% given by Naive Bayes after trying several different learners. Among all machine learners, Naive Bayes performs the best because all champion picks are independent to each other. However, the accuracy is not high because of the internal relations between champions, as well as player’s different level of skills on the same champion. Considering the default value of 50%, a 5.3% boost is a good start on machine learning investigations of this topic. For future improvements, player’s personal skills on certain champions shall also be implemented as an attribute when predicting the result. The internal relationships between champions may also be considered as attributes for future implementations.
1. Riot API: https://developer.riotgames.com.
2. Yuling Shen is in charge of the data acquisition. Both Siran Liu and Jiawen Ou work on the machine learner implementations and website design.
Siran Liu
M.S. in Computer Science
siranliu2016@u.northwestern.edu
Jiawen Ou
M.S. in Computer Science
jiawenou2016@u.northwestern.edu
Yuling Shen
M.S. in Mechanical Engineering
yulingshen2017@u.northwestern.edu